Date: September, 2022 | Category: Quality | Author: Hana Trokic
After almost two years of virtual events, 2022 is bringing things back to how it was pre-COVID-19 pandemic. In-person events are once again in full swing, with live events being the greatest opportunity to grow and build networks and businesses, all the while learning about new trends and innovations in the pharmaceutical industry.
With so many events making their return to venues across the globe, it might be hard to keep track of the growing list of conferences, summits, forums, and expos taking place. As many loyal GlobalVision users and customers work directly or closely within the pharmaceutical industry, we want to help you stay one step ahead of industry updates, trends, and innovations. Don’t fret, we’ve compiled the ultimate list of the top 10 pharmaceutical events happening this fall to ease your woes and keep you on trend. One conference might just be in a city near you.
18th Annual Pharma Forum
- Venue: North Marriott Hotel & Conference Center – Bethesda, Maryland
- Date: In-Person: September 11-14 – Virtual: Live-Stream September 12-14
For those looking for a hybrid event, this one is for you. The 18th Annual Pharma Forum is the largest, most influential conference for pharmaceutical professionals that wish to navigate the future of medical meetings, address compliance implications and execute contracting strategies with virtual, hybrid, and face-to-face event options.
Speakers from AstraZeneca, Allergan, Genentech, and more are waiting to invoke new ideas through their thought leadership speeches on this year’s topic and theme, “Ensure. Evolve. Expand.” Whether you are joining live are watching from the comfort of your own home, this is a must for all who wish to expand their network and stay on trend with new innovations in the industry.
Pharma Japan 2022
- Venue: The Westin Tokyo, Meguro City, Tokyo
- Date: September 28-29, 2022
The most influential forum for Japanese pharma leaders in Marketing, Commercial, Medical Affairs, RWE, and Clinical is happening this fall, returning in person for the first time since 2019.
Like other events happening in fall 2022, this top event will focus on how the pharmaceutical industry faces new challenges. Scientific innovations are no longer enough to be successful as the time has come to go beyond medicine and focus more intensely on patient value. Senior executives, thinkers, and transformers from AstraZeneca, Moderna, Johnson & Johnson, and Bayer Yakuhin will showcase how their dedication and imagination to pave the way for a new era of value and innovation will help patients and the future of healthcare.
Pharma & Patient Europe 2022
- Venue: Nice Acropolis Convention Center, Nice, France
- Date: October 11-13, 2022
You don’t want to miss this one – the world’s leading commercial pharma event. Pharma & Patient Europe is unique as it is one of the first that focuses on patient-centricity and brings Europe’s leaders and patient stakeholders together to truly take a deep dive into patient-centricity in healthcare. Speakers and experts from the world’s top pharmaceutical companies such as Teva, Sanofi, Takeda, Sandoz, Leo Pharma, Novo Nordisk, AstraZeneca, and more, will all come together to share their expertise and insights into patient-first healthcare.
Pharma 2022 is the only place where patient experts, leading solution providers, and pharma changemakers – from commercial, marketing, medical affairs, patient engagement, market access and RWE – commit to business transformation as the catalyst for maximum patient impact.
For those who can’t make it to Nice this fall, be sure to follow the event virtually and not miss a single beat.
Total Health 2022
- Venue: Marriott Marquis, Chicago
- Date: October 20-21, 2022
Total Health 2022 will bring together CEOs, innovators, disruptors, and policymakers to join forces for a vital mission: building a resilient health system through innovation to ensure the gold standard of health for all.
This year’s event will focus on how our healthcare systems have become unsustainable as demand for services is mounting dramatically, the cost of care continues to rise, and populations are suffering worse than ever from unequal access. Keynote speakers from UnitedHealthCare, Atrium Health, Geisinger Health System, and more, will speak about possible solutions while looking at the progress and innovations that are being made in the industry to help the state of healthcare globally.
2022 ISPE Annual Meeting & Expo
- Venue: Gaylord Palms Resort & Convention Center, Orlando, Florida or Virtual
- Date: October 30-November 2, 2022
The 2022 ISPE Annual Meeting & Expo will focus on excellence, modernization, and harmonization in pharmaceutical science and manufacturing across the globe, offering professionals from the pharma industry to grow their network and learn from experts in their field.
With speakers from top institutions such as Cognizant, the FDA, Anvisa, Takeda, and more, this year’s program is filled with informative sessions on the latest developments in the supply chain, operations, facilities, equipment, information systems, product development, production systems, quality systems, regulatory guidance, and cutting-edge industry innovations.
CPhI Frankfurt
- Venue: Messe Frankfurt, Frankfurt, Germany
- Date: November 1-3, 2022
Each year CPHI unites more than 100,000 pharmaceutical professionals through exhibitions, conferences, and online communities to network, identify business opportunities, and expand the global market. It is considered the go-to event for any pharma professional looking to stay relevant and up-to-date in a rapidly changing industry. With the entire pharma industry present from across the entire supply chain, this is the best place to source, connect, and learn exactly what you need to help your business grow.
Pharma Marketing USA 2022
- Venue: Old City Marriott, Philadelphia, USA
- Date: November 8–9, 2022
For those of you who do not want to go across the pond for events in fall 2022, Pharma Marketing USA is just for you. This event will open your eyes to the new world of data-driven, digital engagement in pharmaceutics.
This event will bring 200+ Marketing, Digital, Analytics, Data, Commercial, IT, and Brand leaders together so audiences can learn what capabilities are needed to deploy predictive analytics, develop dynamic content, and venture into new digital channels to meet their client’s needs.
Pharma & Patient USA 2022
- Venue: Old City Marriott, Philadelphia, USA
- Date: November 8–9, 2022
Another event in fall 2022 that will focus on patient centricity, connects the dots across the patient ecosystem at Pharma & Patient USA 2022. This event is where industry leaders and patient advocates will gather together to bridge new partnerships, advance health outcomes for patients in underserved communities, and rebuild trust within the expanding patient community.
With speakers from Sandoz, Novartis, Walgreens, Ipsen, AstraZeneca, and more giving their insights and expertise, this event is the only destination for North American patient-centricity leaders wanting to grow their network and expand their knowledge.
Next HLTH Event
- Venue: The Venetian Expo | Las Vegas
- Date: November 13 – 16, 2022
Like its previous events, HLTH 2022 will gather an entire ecosystem of healthcare professionals for a curated experience that will help accelerate innovation in the healthcare industry.
With an expected 8,500+ attendees, there is never a lack of opportunity to learn, grow, and network at this event. The sessions, agenda, and networking opportunities will foster relevant meetings, introduce you to the right people, and help build new partnerships and connections through one on one opportunities with key solutions providers and sponsors. If you want to accelerate your business and get the key results you are looking for, look no further, this is the event for you.
Global Conference on Pharmaceuticals and Clinical Research
- Venue: Holiday Inn Paris – Porte De Clichy, Paris, France
- Date: November 14-16, 2022
The Global Conference on Pharmaceuticals and Clinical Research provides audiences with an ideal opportunity to network with key opinion leaders and service providers from around the world. Practicing physicians with clinical experience in a variety of treatment areas, as well as members of patient organizations, will be among the attendees.
Pharmaceutical and biotech enterprises, med-tech and medical equipment companies, consulting firms, clinical research organizations, and data management corporations will come together this fall in Paris to share their expertise, experience, and research in pharma.
That’s The Fall Round-Up
With so many great events coming back live for fall 2022 it’s hard to choose which one to attend. Whether you choose to attend them live or join in virtually, one thing is for certain, you’re sure to learn from top industry leaders who will expand your knowledge allowing you to meet your business goals and needs.
If you want to show up prepared for any of these events and brush up on your pharma industry knowledge, take a deep dive into some of the challenges the pharmaceutical industry faces as one of the world’s most highly regulated environments. Read our how-to guide to learn how some of the world’s largest and most successful pharmaceutical organizations have eased and even solved problems due to heavy regulations and have created efficient content creation and review workflows by streamlining every stage of the process. Gain knowledge and insight while having a great ice-breaker to start any networking conversation off right.
Happy fall event-ing to all!
———————————————————————————————————————————————————
Related Articles:
- Solving The Content Efficiency Problem in the Pharma Industry
- Your Complete Guide to Meeting FDA Labeling Requirements
Ensure your content is always error-free in record time with GlobalVision. Try it now for free.
Keep up with the latest updates in automated proofreading software. Sign up for our newsletter.



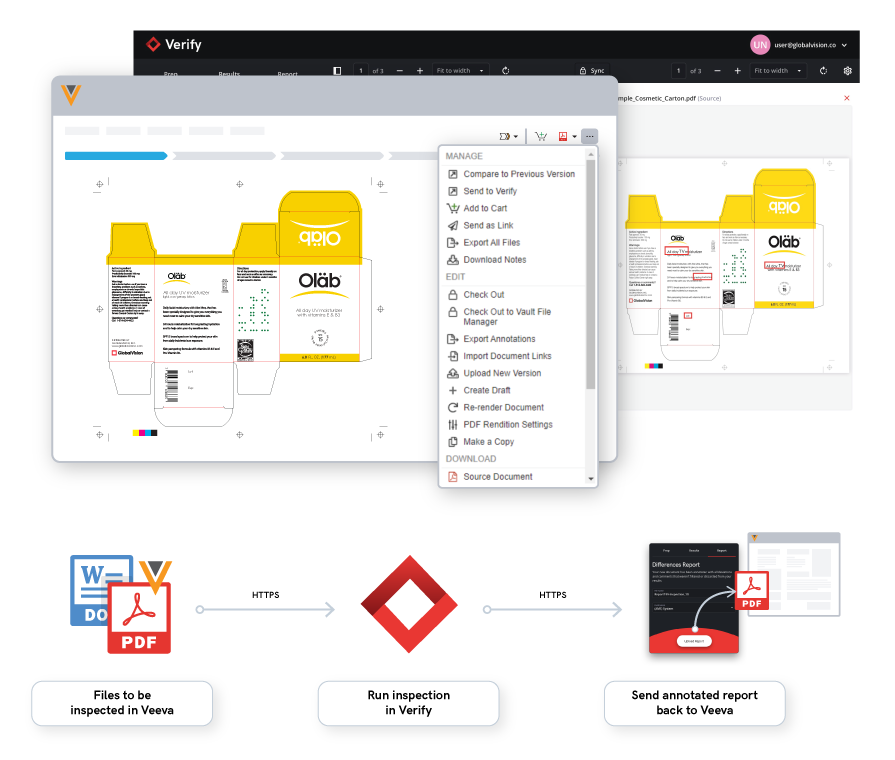







 Consider your product development strategy your roadmap to success. It should cover every step required to take a new product from initial concept to final distribution to make sure you’re well-equipped for the project ahead.
Consider your product development strategy your roadmap to success. It should cover every step required to take a new product from initial concept to final distribution to make sure you’re well-equipped for the project ahead. Your company’s workflow ultimately translates to your organizational efficiency, which can either help or hinder your product’s time-to-market.
Your company’s workflow ultimately translates to your organizational efficiency, which can either help or hinder your product’s time-to-market. Loading your innovative new product with all the bells and whistles can be time-consuming. After all, adding excessive features demands more time and effort and presents opportunities for errors or costly delays.
Loading your innovative new product with all the bells and whistles can be time-consuming. After all, adding excessive features demands more time and effort and presents opportunities for errors or costly delays. Developing every element of your product from scratch is not entirely necessary. It can be a major time consumer when rushing to get your product to market before the competition.
Developing every element of your product from scratch is not entirely necessary. It can be a major time consumer when rushing to get your product to market before the competition. Knowing your strengths and limitations can help achieve rapid time-to-market for your new product. Outsourcing whenever possible allows your organization to efficiently create the desired product experience for your consumers.
Knowing your strengths and limitations can help achieve rapid time-to-market for your new product. Outsourcing whenever possible allows your organization to efficiently create the desired product experience for your consumers. Today’s marketplace and consumer demands are constantly changing. Business agility allows product development to respond to these changes and create innovative solutions to emerging challenges and obstacles.
Today’s marketplace and consumer demands are constantly changing. Business agility allows product development to respond to these changes and create innovative solutions to emerging challenges and obstacles. R&D is quite often the most critical part of a successful product development cycle. It can help your organization better align new offerings to the expectations of consumers while creating an innovative product.
R&D is quite often the most critical part of a successful product development cycle. It can help your organization better align new offerings to the expectations of consumers while creating an innovative product. Data accessibility goes hand in hand with tracking product and process results. Ultimately, greater data transparency helps to accelerate decision-making and improves organizational agility. By increasing data accessibility for the right parties, your team will be equipped with the data needed to make the best decisions for the product, and without a major lag in development times.
Data accessibility goes hand in hand with tracking product and process results. Ultimately, greater data transparency helps to accelerate decision-making and improves organizational agility. By increasing data accessibility for the right parties, your team will be equipped with the data needed to make the best decisions for the product, and without a major lag in development times.
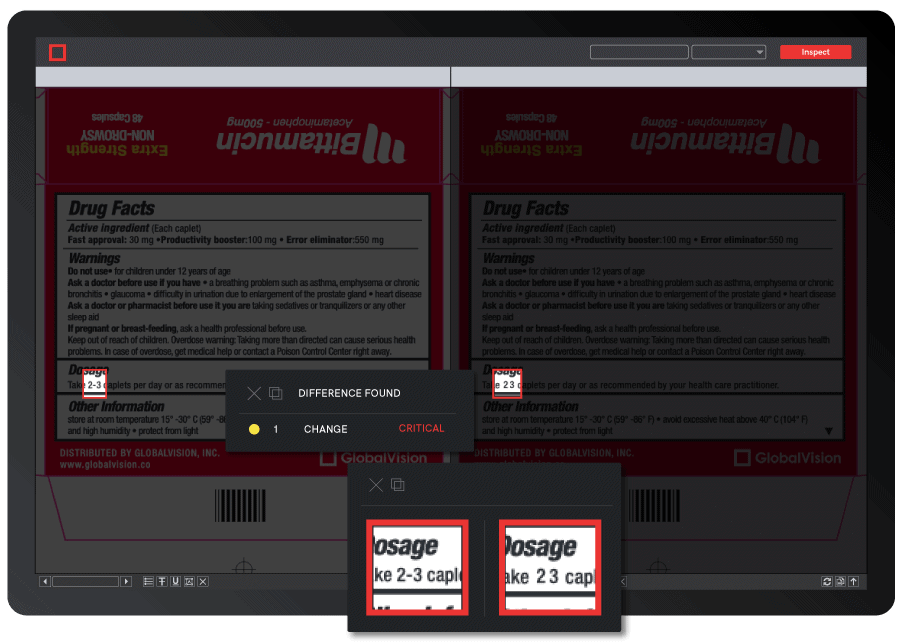


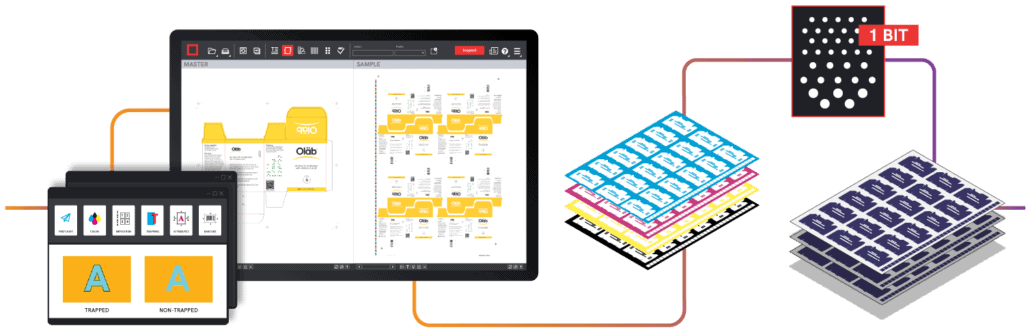
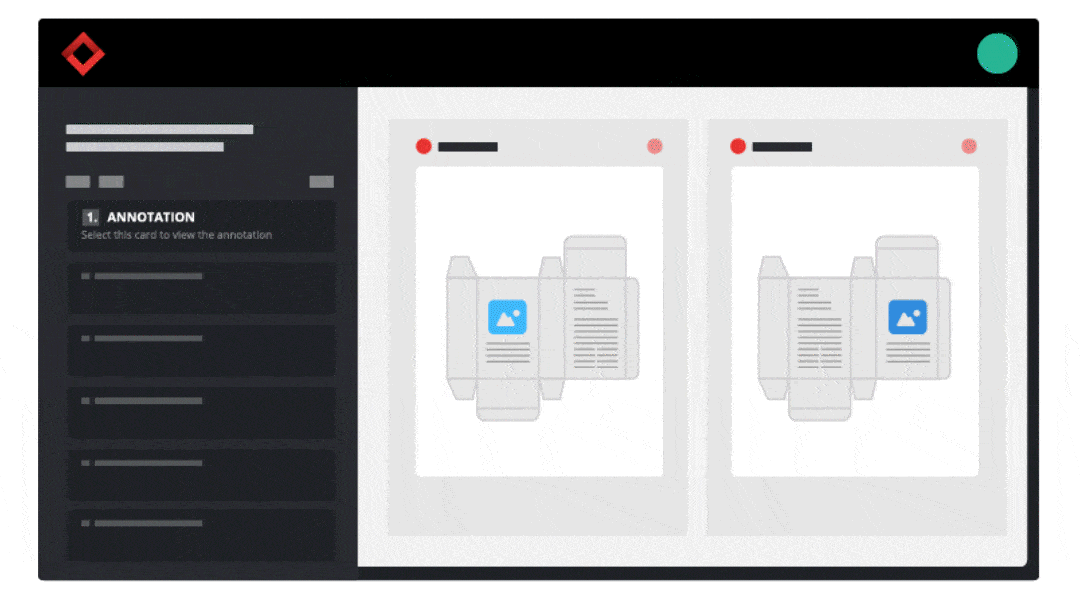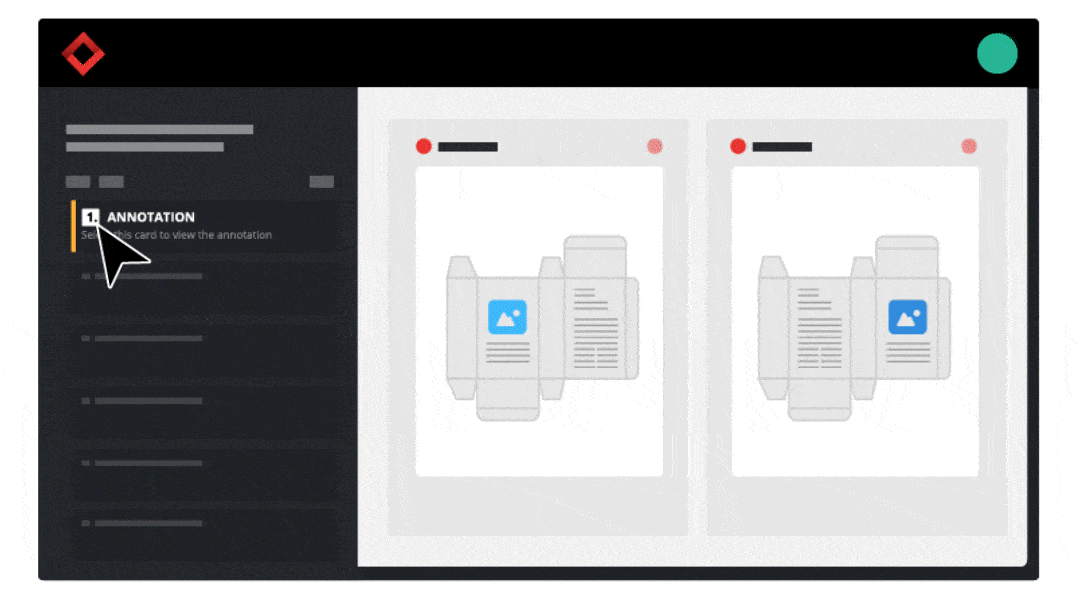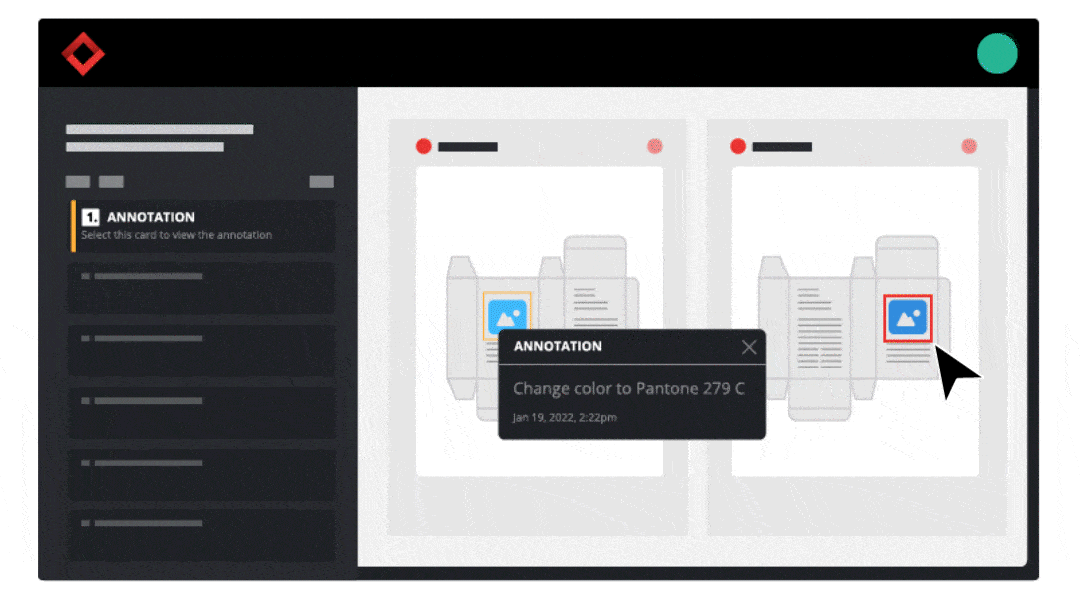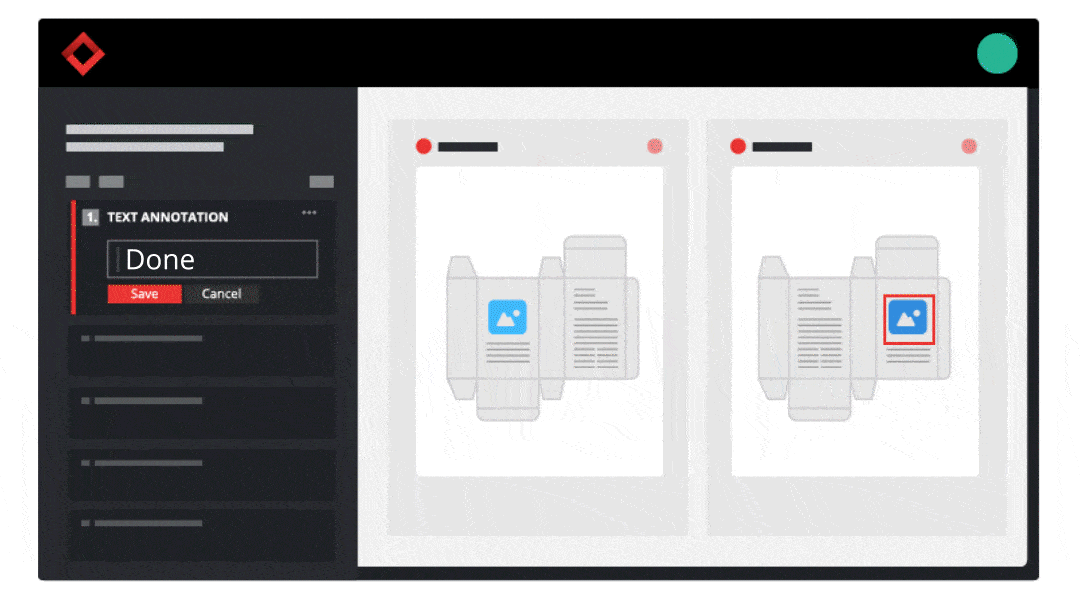
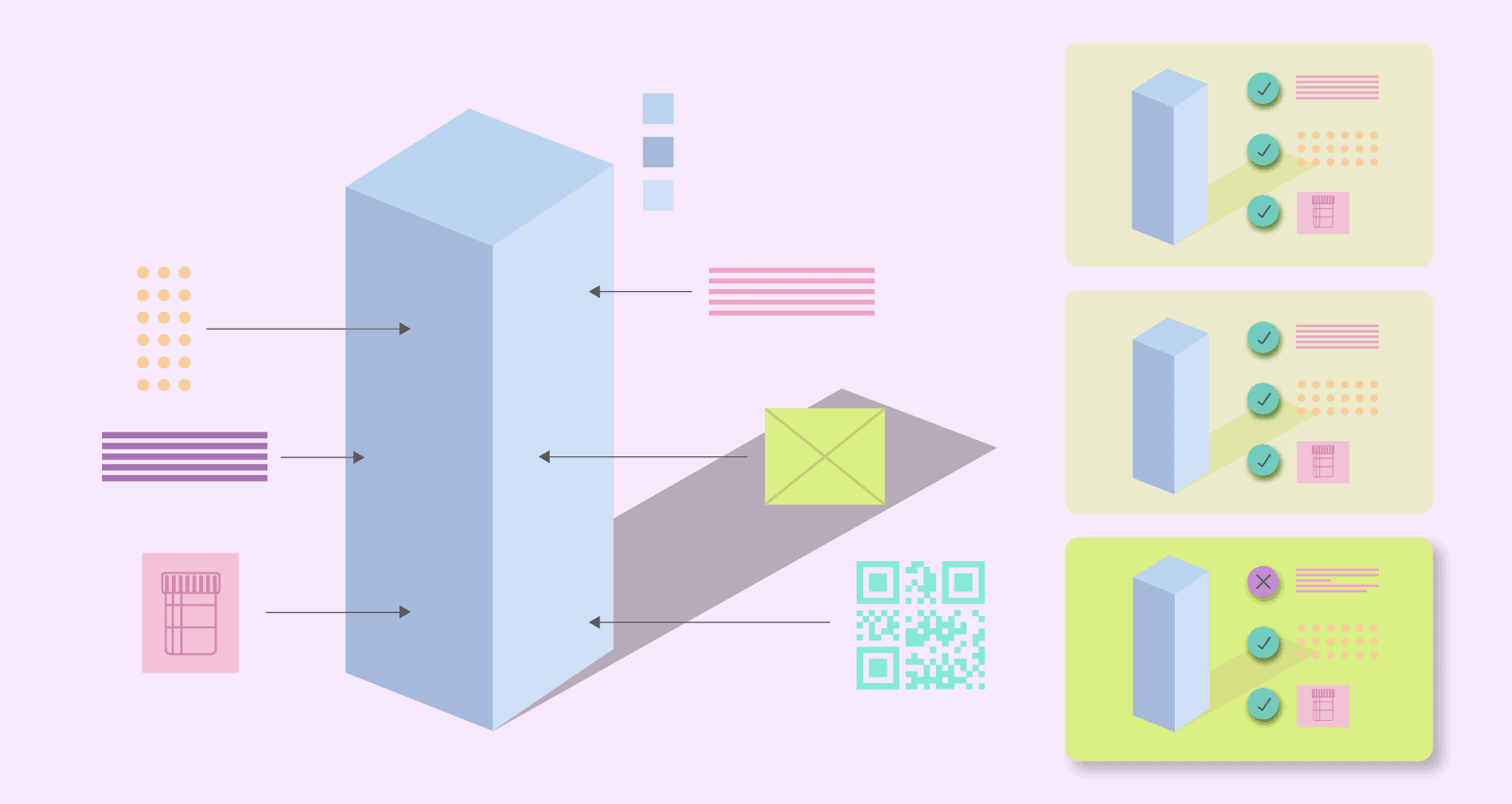 With the majority of resources allocated toward product development and manufacturing procedures, packaging and labeling processes can sometimes be an afterthought.
With the majority of resources allocated toward product development and manufacturing procedures, packaging and labeling processes can sometimes be an afterthought.  1. Standardizing Labeling Procedures
1. Standardizing Labeling Procedures 2. Linking Data Directly to the Source
2. Linking Data Directly to the Source 3. Using Automation Tools to Streamline Workflow
3. Using Automation Tools to Streamline Workflow
 5. Prepare for the Unexpected
5. Prepare for the Unexpected