Date: February, 2023 | Category: Compliance | Author: Hana Trokic
The Food and Drug Administration (FDA) sets strict labeling requirements and guidelines for food, drugs, cosmetics, and medical devices to name a few. The goal of these rules and regulations is to ensure that consumers have accurate and complete information about the products they purchase and consume.
These guidelines cover everything from product ingredients and information, to labeling and packaging requirements. It’s important for manufacturers and distributors to understand and comply with these regulations to avoid potential legal and financial downfalls along with ensuring the complete safety of the consumer.
This post will provide an overview of the FDA’s labeling requirements for specific markets and offer resources on how to stay FDA compliant.
Want to learn more about compliance, proofreading, and quality control? Read more content from GlobalVision here!
What is the FDA?
The Food and Drug Administration, otherwise known as the FDA, is responsible for protecting public and consumer health by ensuring the safety, efficacy, and security of food, drugs, medical devices, cosmetics, and more.
A federal agency within the U.S. Department of Health and Human Services, the FDA is responsible for:
- Reviewing and approving new foods, drugs, cosmetics, and medical devices before they are sold to the public
- Inspecting companies that make and distribute food, cosmetics, drugs, and medical devices
- Monitoring the safety of food, drugs, cosmetics, and medical devices after they have been approved and are on the market
- Providing information to the public about the safety and effectiveness of food, drugs, cosmetics, and medical devices
- Regulating the labeling and advertising of food, drugs, cosmetics, and medical devices
- Enforcing laws that protect consumers from unsafe or misbranded products
What are FDA Labeling Requirements?

FDA labeling requirements are guidelines and regulations set for the labeling of food, drug, cosmetics, and medical device products.
These guidelines ensure that consumers have accurate and complete information about the products they purchase.
The FDA labeling requirements cover a wide range of information, including:
- Packaging and labeling requirements for specific products.
- Ingredient list
- Health claims and nutrient content claims
- Warning statements where applicable
- Nutrition information for food labeling
- Allergens
Manufacturers and distributors must thoroughly understand and comply with all FDA labeling requirements to ensure a safe and reliable product along with getting their products to market faster. They also need to keep updated with FDA regulations as they change over time and manufacturers want to ensure the consistent compliance of their products.
Historical Context of FDA Labeling Requirements
The history of FDA labeling requirements goes back to the late 19th century when the U.S. government first began to regulate the safety and purity of food and drugs. The first federal food and drug law, the Pure Food and Drug Act of 1906, was passed in response to public concern about the safety of food and drugs that were being sold across state lines.
This law required that food and drugs be labeled with accurate information about their contents and prohibited the sale of misbranded or adulterated products.
Over the years, the FDA has continued to update and strengthen its labeling regulations to keep pace with advances in science and technology, as well as changes in consumer preferences.
For example, in the 1960s, the FDA introduced regulations requiring that food labels include nutritional information. In the 1990s, the FDA began to require that food labels list the presence of major food allergens.
The most recent major update to the FDA’s labeling regulations came in 2016 when the agency issued the final rule for the Nutrition Fact Label for packaged foods. This rule, which went into effect in 2020, requires that food labels list the amount of added sugars and gives manufacturers the option to declare the amount of potassium and vitamin D in their products.
In addition to these, the FDA also has updated regulations for different products like dietary supplements, cosmetics, medical devices, tobacco, and others.
FDA Labeling Requirements for Different Markets
FDA labeling requirements vary from market, product, and commodity. Each product, depending on its intention of use, has its own set of requirements that manufacturers need to follow.
The FDA differentiates between markets so that proper instructions and specific requirements can be given to ensure consumer and product safety and avoid recalls, and potential financial losses.
The main markets that will be analyzed in this post are:
- FDA labeling requirements for medical devices
- FDA labeling requirements for drugs
- FDA cosmetics labeling requirements
- FDA labeling requirements for food
Following FDA requirements is complicated. We make it easy.
Keep up with the latest in compliance, quality control, and proofreading by signing up for our newsletter.
FDA Labeling Requirements for Medical Devices

Medical devices can range from simple to complex. Regardless of its complexity, there is a constant amongst them all. They all need to be tested and approved to meet FDA requirements and compliance.
Types of Medical Devices and Their Regulations
A medical device can range from the simplest household item found in everyone’s pantry, like a band-aid, to more complex technology like an x-ray machine. Regulatory authorities globally have put into place risk classifications that group devices into categories based on their potential harm if misused, the complexity of the device, and certain use characteristics.
These classifications are essential to ensure safety and ease the marketing and placement of devices. It also sets a standard for testing where officials know, according to classification, how much testing a device needs to undergo to be deemed safe and ready for patient use.
Medical Device Classification
In the United States, the FDA has classified medical devices into three categories based on the level of control needed to ensure the safety of use. The classifications are:
- Class I – Low risks: Includes devices such as bandages, toothbrushes, floss, and hospital beds. Only requires general controls.
- Class II – Medium Risk: Includes contact lenses, pregnancy tests, and catheters. Requires general controls as well as pre-market notifications
- Class III – High Risk: Includes respirators, prosthetics, and pacemakers. Requires all general controls along with special controls and pre-market approval.
Regulations and Standardizations
Regardless of their classification, it’s important that all medical devices adhere to a certain set of regulations and standardizations. Much like pharmaceuticals, medical devices are treated with similar rigor and are highly regulated.
The FDA offers a detailed overview of all the regulations devices need to follow in order to be deemed fit for use by the general public. The International Organization for Standardization (ISO) sets the standards and convenes them for ease of implementation in the industry.
Some regulations that are put in place for medical devices include:
- Establishment registration
- Medical device listing
- Pre-Market notification
- Pre-Market approval
- Quality system regulation
- Labeling
- Medical device reporting
Labels and Labeling
The FDA defines a label as a “display of written, printed, or graphic matter upon the immediate container of any article” or “all labels and other written, printed, or graphic matter.”
As such, labels are the first point of contact for information for many medical practitioners, patients, and consumers, and need to be accurate to avoid confusion or life-threatening consequences.
The FDA breaks down label regulations for medical devices and clearly defines them by the following:
- General device labeling
- Use of symbols
- Unique device identification
- Good manufacturing practices
- General electronic products
These regulations are in place to primarily ensure that the products and devices in question are being used as they are intended and that the safety of those using them is guaranteed.
For an in-depth look at how you can comply with FDA labeling requirements for medical devices, read our thorough blog post here.
FDA Drug Labeling Requirements

For highly regulated industries like pharmaceuticals, following FDA drug labeling requirements is one of the most crucial aspects of the product lifecycle.
The accuracy of drug labels ensures that patients and consumers are being given proper instructions and dosages of a prescribed drug. Label accuracy also ensures that pharmaceutical companies avoid life-threatening side effects for their consumers, large recalls, and colossal financial downfalls.
The Highly Regulated Pharmaceutical Industry
When it comes to drug labeling, the FDA’s primary purpose and concern are to ensure patient safety and provide healthcare professionals with information about the drug and how it should be prescribed.
Some of the FDA’s drug label requirements include:
- Highlights (a concise summary of label information)
- Full prescribing information
- Recent Major Changes
- Indications and Usage
- Dosage & Administration
- Dosage Forms & Strengths
- Contraindications
- Warnings & Precautions
- Adverse Reactions (listing of most common adverse reactions)
- Drug Interactions
For more information about the importance of FDA drug labeling requirements, read our comprehensive blog post.
FDA Cosmetic Labeling Requirements

All cosmetics marketed globally must comply with provisions set by the governing body of that specific country or region. In the United States, the FDA is responsible for regulating cosmetic labeling with the main goal of ensuring consumer safety and avoiding fraudulent and deceptive statements.
What are Cosmetics?
The FDA defines cosmetics as “articles intended to be applied to the human body for cleansing, beautifying, promoting attractiveness, or altering the appearance without affecting the body’s structure or functions.“
Some products that fall under this category include creams, lotions, perfumes, make-up, shampoos, toothpaste, and deodorants.
While it may seem clear what cosmetics are, manufacturers need to be careful when creating, labeling, and marketing their cosmetic products to ensure they fit under the FDA’s definition and regulations.
If not appropriately labeled, some claims may cause a product to fall under the category of a drug, in which case it has to undergo a set of regulations that differ significantly from cosmetics.
Though sometimes lines can be blurred, manufacturers must understand the difference between cosmetics and drugs and label their products accordingly to avoid potential complications, fines, and recalls.
Cosmetic Labeling
Cosmetic products distributed in the United States must comply with all label regulations established by the FDA. Labels are otherwise considered all written, printed, or graphic matter on or accompanying a product.
The FDA requires that all label statements appear on the inside and outside of the packaging and wrapping.
It is also important to note that false and misleading claims and wrongly labeled products that do not follow FDA cosmetic labeling requirements and regulations may be subject to regulatory action.
How to Correctly Label Cosmetics
To ensure the proper placement of cosmetics on the market and that consumers use them appropriately, manufacturers need to take note of adequate labeling requirements and adhere to them as strictly as possible.
A cosmetic label must contain the following:
- Product identity
- Net contents
- Declaration of Ingredients
- Label warnings
If you want to learn all about FDA cosmetic labeling requirements and how to meet them with complete ease, read our detailed blog post.
FDA Labeling Requirements for Food

Food labels have very defined rules regarding how they should be placed on packages and containers.
General Food Labeling Requirements
Generally speaking, there are two ways to label food:
- Place all required label statements on the front of the label panel.
- Place certain specified label statements on the principal display panel (PDP, or the part of a food label that is most likely to be displayed to the customer when for sale – the front label on a product) and other labeling on the information panel.
No matter the food product, the PDP must display specific information critical for consumers. This includes the food name and the net quantity statement. Food must also include the information panel, which is usually placed to the right of the PDP.
The information panel refers to statements that are generally required to be placed together. They usually include information such as the name and address of the manufacturer, ingredient list, nutrition labeling, and allergy labeling.
It is also important to note that label standardizations must be followed to ensure consistent and easy-to-read labels.
The FDA requires that you use a prominent print size and that the font is clear and legible through specified letter height. Additional formatting is also detailed in FDA guidelines to ensure that text is easy to read on different backgrounds and artwork.
Manufacturers must also ensure that all of their food labels contain the following:
- Name of food
- Net quantity of contents statements
- Ingredients list
- Food allergen labeling
- Nutrition labeling
- Nutrition content claims
Want to take a deep dive into FDA food labeling requirements? We have the blog post just for you.
How to Meet FDA Labeling Requirements
Regardless of the food, drug, cosmetic, or medical device you want to send out to market, there are constants among them all that help ensure their safety and quality.
Best Practices for Preparing Labels for FDA Review
There are several best practices for preparing labels for FDA review:
- Ensure that the label accurately reflects the contents of the product and that it meets all legal requirements for labeling.
- Include all required information, such as the product’s name, ingredients, and nutritional information when needed.
- Provide detailed information about the product, including how to use it, storage instructions, and any other relevant information.
- Make sure that any health or safety claims are supported by scientific evidence and are not misleading.
- Provide allergen information, if any, on the packaging when needed.
- Use clear and conspicuous language that is easy to read and understand.
- Use appropriate formatting and layout to make the label easy to read, including using contrasting colors and appropriate font sizes.
- Make sure that the label is consistent with any advertising or promotional materials for the product.
- Provide contact information for the manufacturer or distributor, such as address, phone number, or website.
The Importance of Label Accuracy
When we look at highly regulated products such as pharmaceuticals, cosmetics, and medical devices, the first thing our eyes go to, is the label. This is where we know we will find all the information needed about that said product.
The information stated on that very piece of content determines whether or not a consumer will find the product suitable and reliable enough to purchase and use. Because of this, the accuracy of labels should be of high priority.
Label accuracy is crucial as it details the products:
- Safety: Accurate labels ensure that consumers are aware of any potential hazards or allergies associated with the product, which can help prevent harm or injury.
- Legal compliance: Accurate labels help ensure compliance with these regulations and reduce the risk of fines or legal action.
- Trust and credibility: Accurate labels help build trust and credibility with consumers, as they demonstrate that a company is committed to providing honest and transparent information about its products.
- Liability: Inaccurate labeling can lead to product liability claims from consumers who have suffered harm or injury as a result of using a product.
In order to have only the highest quality products making it into the hands of consumers, label accuracy should be a top priority throughout the entire product development process. It is important to proof, check, and, review, labels to ensure that they are accurate, complete, and up-to-date.
Common Label Mistakes to Avoid
As inaccurate labels can lead to disastrous consequences for highly regulated industries, proofreading, reviewing, and checking labels should be a thorough and precise process. Mistakes should be avoided by any means necessary.
Some common label mistakes that manufacturers should avoid include:
- Incorrect or incomplete information: Failing to provide all required information or providing incorrect information on a label.
- Poor readability: Using small font sizes, poor contrast, or a confusing layout can make it difficult for consumers to read and understand labels.
- Inadequate allergen labeling: Failing to properly label potential allergens can lead to serious health consequences for certain individuals.
- Outdated information: Failing to update a label with new information, such as changes in ingredients or nutritional information, can be misleading to consumers.
- Non-compliance with regulatory requirements: Labels must comply with all applicable laws and regulations, such as those related to nutrition, health and safety claims, and ingredient labeling.
- Misleading or false claims: Making false or misleading claims on a label can result in legal action and damage to a company’s reputation.
Best Practices for Maintaining FDA Label Compliance

With many rules, regulations, and requirements to follow, it’s no surprise that such heavy importance is placed on label accuracy. For perspective, in drug labeling, it is estimated that over 50% of medication use errors are associated with poor labels.
Though this includes patient misunderstandings, it is generally believed that implementing standardizations such as text, language, typography, and other display standards will drastically reduce errors in drug labels.
Along with patient safety, it is also important to note that labeling errors lead to significant recalls and financial losses, which are more frequent than one would think.
Clinically important drug recalls occur approximately once per month in the United States. For perspective on just how significant these financial impacts can be, Johnson and Johnson lost roughly $600 million in sales after closing a distribution site due to a recall.
Because of this, best practices should be put in place to ensure that labels are accurate while maintaining manufacturing and distribution efficiency and speed.
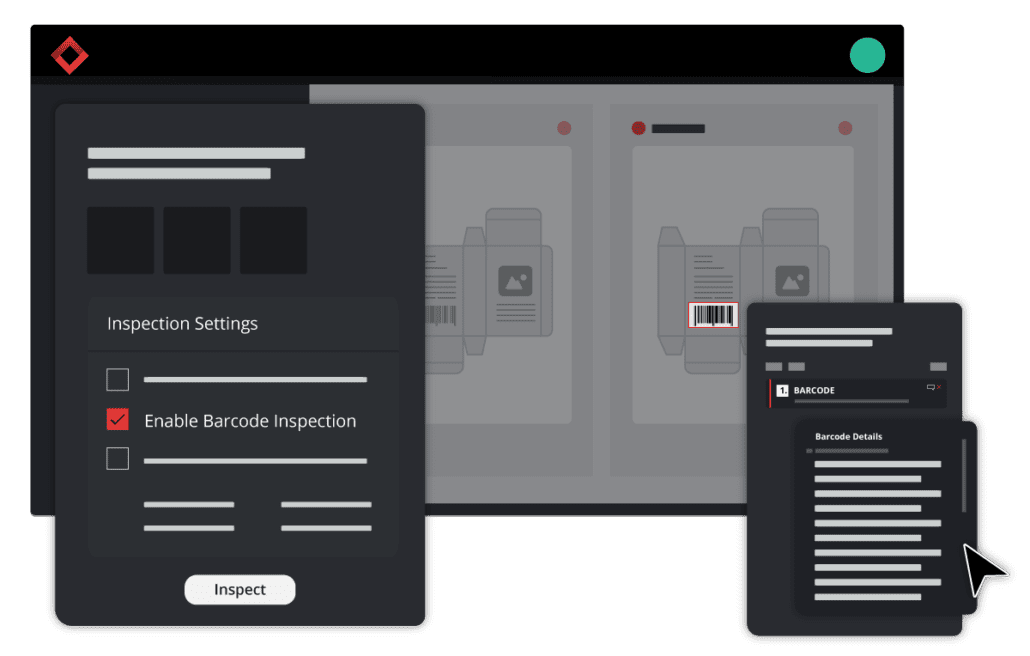
One certain method that ensures label accuracy is the implementation of automated quality control, or more precisely, a file comparison tool to check content and labels with complete ease and efficacy.
What is File Comparison Technology?
Content for highly regulated products is produced at such rates and numbers that companies need to turn to technology to help ensure the accuracy of their content and labeling along with all technical documentation.
In other words, file comparison technology is the ideal solution they are looking for.
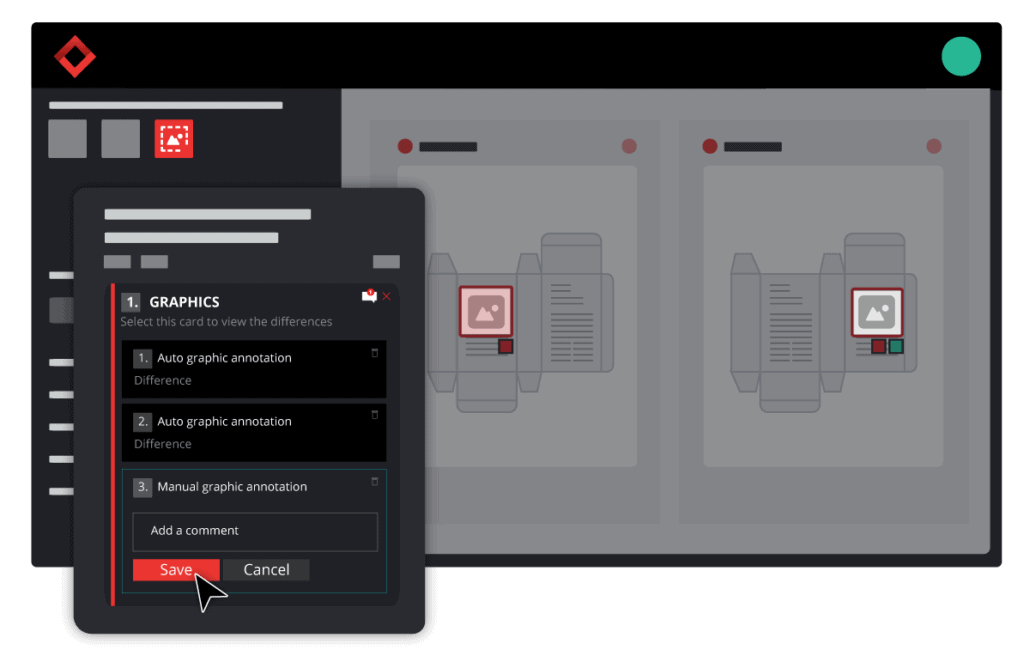
File comparison technology proofreads documents and files in seconds. The software works by overlaying two files to find discrepancies between the two. No matter how small the errors or differences may be, the software will detect them and pinpoint their exact location on the file.
The software can detect errors in copy and artwork that is nearly impossible to see with the naked eye. Using a document comparison tool, errors and differences can be easily found in text, graphics, barcodes, braille, print, and color.
The result is proofread and error-free labels and packaging in record time – every time.
By introducing file comparison technology to your proofreading and reviewing processes, quality control departments in regulated industries can avoid unnecessary and hasty product mistakes that can be easily corrected and avoided.
The technology gives manufacturers confidence that their products and accompanying labels reach the hands of consumers in pristine condition – down to the last period.
Find out more about how file comparison technology can help quality control teams in regulated industries.
Your New Automated Solution
Many large global corporations in highly regulated industries have yet to implement new technologies that increase workflow efficiency.
In some cases, many still rely on manual and labor-intensive proofreading and reviewing processes prone to mistakes, leaving huge potential for operations to be optimized and streamlined for maximum efficiency.
Automated quality control or a file comparison tool inspects content and artwork with complete ease, lightning speed, and increased accuracy.
To keep up with increasing global consumer demands, regulated industries create an immeasurable amount of products, each with its own packaging, labeling, and documentation. This content must be meticulously reviewed and proofread to ensure that the final product is error-free.
Manually proofreading this amount of content is not an efficient solution for companies that need to keep up with growing demands. File comparison software offers a foolproof solution to ensure all this generated content is checked and proofread perfectly.
This advancement in proofreading processes eliminates the need for manual document inspections and leaves it up to technology. The software conducts digital checks for discrepancies in text, spelling, graphics, color, and more.
The software conducts thorough inspections in a fraction of the time and ensures that labels and content are 100% accurate before going out to the hands of patients and consumers.
This technological advancement ultimately increases productivity and workflow efficiency and offers endless benefits unmatched by manual inspections. Not only does automated proofreading software help ease the proofreading process, it simply makes proofreading better.
Keep Up with FDA Labeling Requirements
If you want to keep up with FDA labeling requirements with complete ease, switch to automated quality control. A trusted technology, GlobalVision’s innovative automated solutions have been solving problems for regulated industries globally for over thirty years.
By using GlobalVision to eliminate time-consuming and inaccurate manual checks, the largest pharma companies worldwide cut review times by 89%. Just by making the simple switch to automated quality control, top companies got critical healthcare products into the hands of consumers faster and with complete confidence that their labels and content are 100% accurate and FDA compliant.
To name only a few, GlobalVision has helped:
Ensuring that you meet all FDA drug labeling requirements is far from easy. Yet, through the simple introduction of automated quality control, companies can rest assured that they are drastically eliminating the risk of human error, getting their product to market faster with fewer revision cycles, and reducing the risk of costly recalls and misprints.
Ready to Automate Your Workflows?
To ensure market success and error-free, perfect labels, regulated industries must streamline their quality control processes. The simple Implementation of file comparison technology helps teams create flawless labels, speeds up the content creation process and revision times, and gets products to market in record time.
The benefits a file comparison tool brings to manufacturers are countless and, in most cases, are a crucial company resource. The only way manufacturers can be completely confident that their content and products are error-free is through fast, accurate, and trusted software such as file comparison technology.
Ready to step into the world of automated proofreading? Request a demo of our innovative text comparison software and see how this technology can revolutionize your everyday business practices. Transform your quality control processes with GlobalVision’s cloud-based quality inspection tool.
Also, to learn more about how technology can help manage regulatory compliance, check out GlobalVision’s guide Digital Transformation for Pharmaceutical Packaging Quality.
———————————————————————————————————————————————————
Related Articles:
Ensure your content is always error-free in record time with GlobalVision. Try it now for free.
Keep up with the latest updates in automated proofreading software. Sign up for our newsletter.


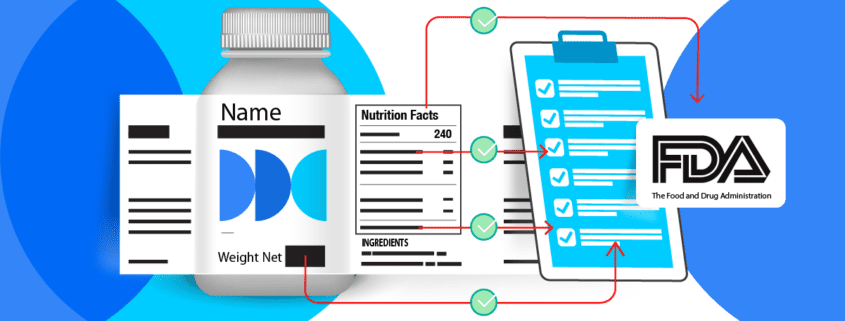


 Food labels are critical. Not only do they provide vital information to consumers about the food choices they are making, but they are also legally and governmentally mandated and regulated. Those labels we see and read daily are crucial to ensuring the health and safety of the general public and consumer.
Food labels are critical. Not only do they provide vital information to consumers about the food choices they are making, but they are also legally and governmentally mandated and regulated. Those labels we see and read daily are crucial to ensuring the health and safety of the general public and consumer.







 If you want to keep up with FDA drug labeling requirements with complete ease, switch to automated quality control. A trusted technology,
If you want to keep up with FDA drug labeling requirements with complete ease, switch to automated quality control. A trusted technology,